
[Paper Review] Extremely Simple Activation Shaping for Out-of-Distribution Detection
논문 링크 : ASH
Extremely Simple Activation Shaping for Out-of-Distribution Detection 논문 리뷰입니다.
Introduction
머신 러닝은 반복을 통해 작동한다. 더 나은 학습 기술을 개발하고, 모델을 학습 시킨 후 배포 과정에서 발생하는 문제, 한계 등을 관찰하여 학습과정을 수정하거나 개선한다. 그러나 large model의 시대에 들어오면서, 확장(scaling) 발전에 크게 영향을 받고 있다. 그 결과, train-deployment loop를 여러번 하기 어려워지고 있어서 post-hoc 기법이 더 선호되고 있다. 특징 후 처리(feature post processing)와 같은 방법은 사후 작업을 활용하여 사전학습된 일반적이고, 유연한 모델이 downstream application에 더 적응하도록 만든다.
배포 과정에서 자주 관찰되는 문제 중 하나는 분포 외 일반화 실패(Out-of-Distribution generalization failure) 이다.
OOD Detection에서의 중요한 질문은 "Do model know when they don't know?" 모델이 모르는 것을 모델이 알 수 있는가? 이다. 충분히 학습된 Neural Network의 경우 학습에 사용된 데이터의 분포 외 데이터에 대해서는 낮은 신뢰도나 높은 불확실성 값을 출력해야 하지만 그렇지 않은 경우가 많이 존재한다.
많은 연구자들은 OOD detection 실패의 원인을 NN의 불완전한 보정(poor calibration)이라고 한다. 이를 해결하기 위한 노력을 통해 OOD detection의 성능은 크게 발전했지만, OOD detection과 ID accuracy간의 Pareto Frontier를 확립할 여지가 남았다.
본 논문에서는 학습되거나 테스트된 데이터 분포에 대한 지식이 없다는 가정하에서 사전 학습된 Network에 약간의 변형을 통해 OOD detection task를 해결하고자 한다.
- ReAct : 특정 layer에서 activation pattern이 ID와 OOD간의 큰 차이를 보인다.
- DICE : 특정 층의 weight를 sparsification하는 방법의 연구

매우 간단한 Activation SHaping(ASH) 방법은 feature representation(일반적으로 penultimate layer)을 사용하여 2단계로 작동한다.
- 간단한 Top-K 기준에 따라서 activation값 중 대다수(e.g. 90%)를 제거한다.
- 나머지(e.g. 10%) activation값을 변환한다.
이 작업 이후 Network의 나머지 부분을 통과하여, classification과 OOD detection score를 생성한다.
Advantages of ASH
- 학습 데이터에 대한 global threshold값을 사용하지 않으므로 완전히 post-hoc 방식
- 적용할 수 있는 layer에 대해 유연
- ID accuracy를 잘 유지하여 우수한 Pareto frontier를 구축
The Out-of-Distribution Detection Setup
OOD detection은 일반적으로 아래의 과정을 따른다.
- ID(in-distribution) data라고 불리는 데이터를 사용해 모델 학습
- 추론 시점에 OOD(out-of-distribution) data를 모델에 입력
- 모델의 출력에서 score를 도출해 입력값이 ID인지 OOD인지 구분
- 다양한 평가 지표(AUROC, FPR@95, AUPR)를 사용하여 detector평가
Step 1 ~ 2

- DenseNet-101을 이용해 CIFAR-10, CIFAR-100을 ID data로 하는 OOD detection task 실험
- ResNet50, MobileNetV2를 이용해 ImageNet을 ID data로 하는 OOD detection task 실험
Step 3
일반적으로 사용되는 score function으로는 Softmax output, Energy score가 있다. Energy score가 Softmax score보다 더 우수한 성능을 보이기에 본 연구에서는 Energy score를 활용하였다.
주어진 input $\mathbf{x}$와 학습된 network $f$에 대해 Energy function $E(\mathbf{x};f)$는 network의 logit 출력 $f(\mathbf{x})$를 scalar값으로 변환한다.
$$
E(\mathbf{x};f)=-\log\sum_{i=1}^{c}e^{f_{i}(\mathbf{x})}
$$
- $c$ : number of classes
- $f_{i}(\mathbf{x})$ : logit output of class $i$
OOD detection에서 사용되는 score는 negative energy score로 $-E(\mathbf{x};f)$ 이다. 따라서 ID data가 더 높은 점수를 가지고, OOD data는 낮은 점수를 가진다.
Step 4
OOD detection에서 사용되는 평가지표는 아래와 같다.
- AUROC$\uparrow$ : Receiver Operating Characteristic curve 아래 면적으로, detector의 전체적인 성능을 측정한다.
- AUPR$\uparrow$ : Precision-Recall curve아래 면적
- FPR95$\downarrow$ : True Positive Rate가 95%일 때 OOD가 ID로 잘못 분류될 확률
Activation Shaping for OOD Detection
본 논문에서는 현대에 over-parameterize된 Deep Neural Network가 생성하는 representation이 과해 이를 단순화 하더라도 원래의 성능(e.g. classification accuracy)에는 큰 영향을 미치지 않으면서, 다른 task(e.g. OOD detection)에서 놀라운 성능 향상을 가질 수 있다는 가설하에 ASH 방법을 통해 실험하였다.
아래는 ASH method이다.
- activation값 대부분을 제거
- 전체 representation의 $p$-percentile에 해당하는 threshold $t$를 계산
- $t$이하의 모든 activation값을 0으로 설정
- 제거되지 않은 activation값 처리
- ASH-P : 단순히 activation값을 0으로 설정하는 것. ASH-B, ASH-S의 성능 향상을 비교하기 위한 Baseline
- ASH-B : 나머지 activation값을 일정한 양의 상수로 할당하여 representation을 이진화
- ASH-S : Pruning전 후의 activation값의 합을 기반으로 비율을 계산해, 나머지 activation값의 크기를 조정(Scaling)

ASH는 중간 layer에서 input의 feature representation에 대해 실시간(on-the-fly)로 적용되며 이후 Network의 나머지 경로를 통해 forward path가 진행된다. ASH를 통한 output은 Classification 뿐만 아니라 OOD detection에도 사용된다. 따라서 ASH는 original task와 OOD detection에 추가적인 computational cost없이 모두 작동하는 unified framework이다.
Placement of ASH
- ImageNet
- ASH는 Network의 마지막 average pooling layer이후 적용
- ResNet50에서 feature map의 크기 : $2048 \times 1 \times 1$
- MobileNetV2에서 feature map의 크기 : $1280\times1\times1$
- CIFAR
- ASH는 penultimate layer이후에 적용
- DenseNet-101에서 feature map의 크기 : $342 \times 1\times1$
The $p$ parameter
ASH는 단 하나의 parameter $p$를 가지는데 실험에서 $p$는 60~90사이로 변화하여 관찰하였고, 비교적 안정적인 성능을 보였다.
각 task에 대해 최적의 $p$는 아래와 같다.
- ImageNet
- ASH-S : $p = 90$
- ASH-B : $p = 65$
- CIFAR-10, CIFAR-100
- ASH-S : $p = 95$, $p = 90$
- ASH-B : $p = 95$, $p = 85$
Results
ASH offers the best ID-OOD Tradeoff
Network의 output에서 직접 score를 얻는 Energy, Softmax, ODIN과 같은 방법은 ID accuracy는 유지하지만, OOD detection 성능은 상대적으로 낮고, Network의 weight나 representation을 수정하는 ReAct, DICE와 같은 방법은 ID accuracy 손실을 어느 정도 감소해야한다. 하지만 ASH는 ID task와 OOD task 모두 강력한 성능을 보여준다.
OOD Detection on both ImageNet and CIFAR Benchmarks

FPR95, AUROC를 기준으로 평가하였다.
- ImageNet
- ASH-B, ASH-S는 ResNet을 사용한 task에서 거의 모든 OOD dataset에서 SOTA의 성능을 달성
- ASH-P는 단순히 pruning을 하는 것 만으로 성능향상을 보여준다.(Energy, Softmax, ODIN 능가)

- CIFAR
- ASH의 변형이 기존의 성능을 크게 능가하였다.
On Preserving In-Distribution Accuracy
ASH는 In-distribution 성능을 유지하기 때문에 ID와 OOD 작업 모두에서 사용할 수 있는 unified pipeline으로 활용될 수 있다.

- ASH-S, ASH-P모두 낮은 pruning비율(65%)에서 ID accuracy에 거의 영향을 미치지 않는다.
- Pruning비율이 증가할수록 accuracy감소가 커진다.

- ASH-S, ASH-P는 상당히 높은 pruning 수준까지 ID accuracy를 유지한다.
- ASH-B는 pruning 비율 50
90%까지 ID accuracy가 증가하는 경향을 보이며, 8090%사이에서 best accuracy가 달성된다. - ASH-B의 극단적인 이진화는 pruning비율이 낮을수록 더 많은 값이 변경되므로 classification성능에 더 큰 영향을 준다.
- 0일 경우 모든 값을 평균값으로 계산하여 classifier를 망가뜨림.
ASH-RAND: Randomizing Activation Values

ASH-B에서 모든 값을 0 또는 양의 상수로 설정하는 실험의 성공을 바탕으로 ASH-RAND라는 activation shaping의 범위를 더욱 확장한 실험을 진행했다.
- ASH-RAND는 pruning후 나머지 activation값을 0 ~ 10 사이의 random값을 할당
- 확장한 실험에서도 합리적인 성능을 보임
Ablation Studies
Global vs local threshold

ASH의 작동방식은 local threshold를 사용하여 on-the-fly로 각각의 이미지마다 pruning threshold $t$를 계산한다. 즉, 입력 이미지마다 서로 다른 threshold값으로 pruning이 수행된다.
Global threshold는 모든 train data를 활용하여 threshold값을 설정하는 것이다.
- CIFAR-10의 50000개의 image data
- ResNet50의 penultimate layer의 activation value $f(\mathbf{x}_{i}) \in \mathbb{R}^{2048}$
- $50000\times 2048$에서 $t = P_{90}$
동일한 pruning 비율에서 local threshold값을 사용하는 방식이 더 나은 성능을 보였다.
Where to ASH

ASH-S를 수행한 결과 Pruning 비율에 따른 accuracy 저하는 Network의 초반 layer로 갈수록 더 심각해진다.
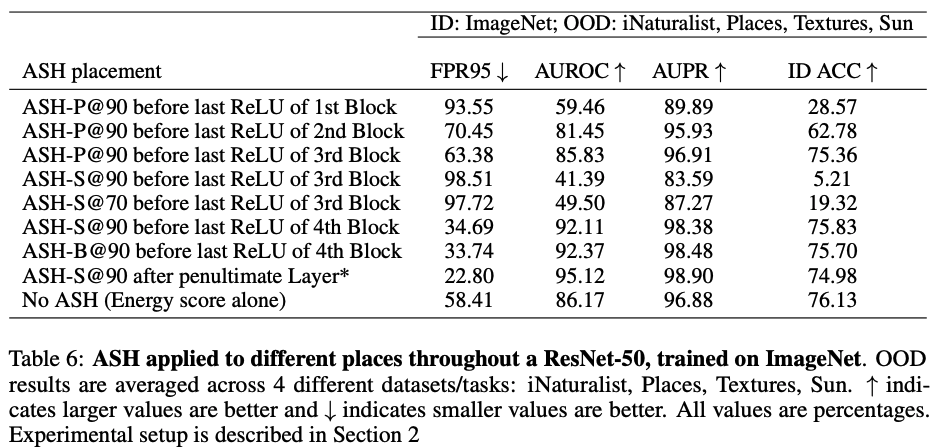
Figure 5를 보면 Block4에서 ASH-S를 적용하였을 때 ID accuracy가 높은 것을 알 수 있다. 하지만 Table 6을 보면 OOD 성능이 penultimate layer에서 성능이 더 좋은 것을 알 수 있다. 따라서 본 논문에서는 penultimate layer에서 ASH-S를 적용하는 것이 최적이라고 하였다.
Plug-and-play ASH to other methods

ASH는 기존의 다른 방법들과 매우 높은 호환성을 가진다.
Related Work
Sparse representation과 관련한 Stochastic activation pruning(SAP)논문을 참고하면 좋을 것 같다.
Conclusion
- ASH는 매우 간단하고, post-hoc방식에 실시간(on-the-fly)으로 동작하며 plug-and-play방식으로 추론 시 입력 데이터에 적용되는 activation shaping기법이다.
- OOD detection성능과 ID classification성능 간 최상의 trade-off를 제공한다.
- activation 값을 수정하면서 class-dependent한 부분과 class-agnostic한 부분의 경계를 찾을 수 있으면 추후 연구에 도움이 될 것 같다.
Question about the power of ASH
- 왜 feature map에 변화를 주는 것이 OOD detection 성능을 향상시키는가?
- 왜 대부분의 activation값을 제거해도 정확도에 큰 영향을 미치지 않는가?
- feature representation이 중복된 것은 아닌가?
ASH는 feature cleaning 또는 post-hoc regularization으로 간주할 수 있다.
현재 Deep Neural Network가 overparameterized 되어 있다는 점은 모두가 인정하는 사실이다. 따라서 Network가 학습하는 representation은 과도하게 표현될 가능성이 있다. 즉 input에 대해 생성된 representation에는 불필요한 중복이 과도하게 표현된다.
이런 이유로 학습 이후 간단한 feature cleaning단계가 학습된 표현을 더 효과적으로 다듬는 데 도움을 줄 수 있다고 추측한다.
Pruning 후 남은 activation 값은 중요한 정보를 더 잘 반영하여 ID와 OOD 간의 차이를 극대화한다. 이는 실험의 결과로 알 수 있다.
