

[Paper Review] Your Out-of-Distribution Detection Method is Not Robust!
논문 링크 : ATD
Your Out-of-Distribution DetectionMethod is Not Robust! 논문 리뷰입니다.
Introduction
Neural Network의 발전은 Object detection, image classification과 같은 실제 응용 분야에서 광범위한 활용을 이끌어 냈다. 이런 모델을은 높은 일반화 능력을 가지고 있어서, train data에 속하지 않는 sample에 대해서도 임의로 높은 확률을 할당하는 경우가 있다. 이러한 현상은 의료 진단이나 자율주행과 같이 이상 데이터를 다르게 처리해야 하는 안전이 중요한 분야에서 문제를 일으킨다.
본 논문에서는 OOD(Out-of-distribution)를 식별하는 문제를 해결하기 위한 다양한 모델들이 input data에 가해지는 adversarial perturbation에 대한 robustness 측면에서 검증이 필요하다고 한다.
- OOD detection은 학습에 사용된 데이터 분포와 다른 훈련되지 않은 새로운 유형의 데이터를 구분하는 기술
- 딥러닝 모델이 예상치 못한 입력에 대해 잘못된 판단을 내리는 문제를 줄이기 위해 필수적이며, 안정성과 신뢰성을 높이는 데 중요하다.
Deep Network는 adversarial example에 취약하다.
- adversarial example이란 제한된 크기의 작은 perturbation이 가해져 모델의 예측 오류를 크게 유발하는 input을 의미한다.
이 현상은 image classification에서 처음 발견되었으나 OOD detection 방법도 adversarial example로 인해 어려움을 겪는다. 작은 perturbation만으로도 ID(in-distribution) data가 OOD로 분류되거나 그 반대가 발생할 수 있다.
Robust OOD detection은 Adversarial attack에 대한 robustness와 OOD detection의 정확성을 연결하는 지점이다. 이전 연구들에서 다양한 방법들이 제안되었지만, classifier만 공격하여 detection성능을 평가하는 문제, classification 정확도를 보호하기 위해 작은 perturbation을 주거나 ID data는 공격하지 않는 문제가 존재하였다.
본 논문에서는 이전 방어 방법들과 OOD detection 방법을 end-to-end PGD 공격에 대해 평가하였다.

CIFAR-10 dataset에서 ϵ=8255의 binary OOD detection 상황에서 대부분의 방법들이 무작위 추정보다 못한 성능을 보였다.
이전 방법들의 한계를 극복함으로써 강인한 모델을 설계하기 위해 GAN 기반 방법을 사용해 OOD sample을 생성하고 ID data와 구분하는 Adversarially Trained Discriminator (ATD)를 제안한다.
이상적인 generator는 discriminator를 속이며, 그 결과 open set에서 adversarial output을 만들어 낸다. 이는 discriminator가 open set에 대한 adversarial attack에 대해 implicit robustness를 갖게하는 효과를 낸다. 또한 이 논문에서 소량의 real OOD data를 이용해 adversarial training을 수행하여 이에 대해서도 robustness를 확보한다. 위 그림에서 ATD가 이전 방법들을 크게 능가함을 보여준다. 이전 방법들의 취약성을 밝혀내고 해결책을 제시함으로써 이 분야에 중요한 진전을 이루었다.
Background
Out-of-Distribution Detection
Probabilities
- 이상 탐지를 위한 간단하면서도 효과적인 방법 중 하나는 Maximum Softmax Probability(MSP)이다.
- 이 방법은 K개의 class를 가진 classifier에 적용되며, sample x에 대해 max를 점수로 반환한다.
Distances
- 이상 sample은 class conditional distribution과의 거리를 통해 탐지할 수 있다.
- Mahalanobis distance(MD)와 Relative MD(RMD)가 주요 방법이다.
- K개의 class를 가진 ID data에 대해 pre-logit z' 에 class conditional gaussian distribution N(\mu_{k},\Sigma)를 적합시킨다.
\mu_k = \frac{1}{N_{k}} \sum_{i : y_{i} = k} z_{i}, \quad \Sigma = \frac{1}{N} \sum_{k=1}^K \sum_{i : y_{i} = k} (z_{i} - \mu_{k})(z_{i} - \mu_{k})^T, \quad k = 1, 2, \ldots, K
- RMD를 사용하기 위해서는 전체 ID data에 대해 N(\mu_{0},\Sigma_{0})를 적합시킨다.
MD_{k}(z') = (z' - \mu_{k})^T \Sigma^{-1} (z' - \mu_{k}), \quad RMD_{k}(z') = MD_{k}(z') - MD_{0}(z')
score_{MD}(x') = -\min_{k} { MD_{k}(z') }, \quad score_{RMD}(x') = -\min_{k} { RMD_{k}(z') }
Discriminators
- 이전 방법들은 K-classifier를 기반으로 score function을 정의했지만, 직접 binary discriminator를 학습시킬 수도 있다.
- Outlier Exposure는 일부 Outlier를 활용하여 open set구분을 위한 binary discriminator를 학습한다.
Adversarial Attacks
input x와 ground-truth label y가 주어졌을 때, adversarial example x^{\ast}는 예측 모델의 손실 J(x^{\ast},y)를 최대화 하도록 x에 작은 noise를 더해 생성된다. adversarial noise의 l_{p} norm은 \Vert x - x^{\ast} \Vert_{p} \le \epsilon 이어야 하며, 이는 이미지의 의미적 변화가 없도록 보장하기 위함이다.
Fast Gradient Sign Method (FGSM)는 손실 함수의 gradient 부호 방향으로 단일 스텝을 진행하여 손실을 최대화 한다.
x^{\ast}=x+\epsilon \cdot sign(\nabla_{x}J(x,y))
더 작은 step 크기 \alpha로 반복 수행할 수 있는데
x_{0}^{\ast}=x,\quad x_{t+1}^{\ast}=x_{t}^{\ast}+\alpha \cdot sign(\nabla_{x}J(x_{t}^{\ast},y)) 각 step마다 noise는 반경 \epsilon인 l_{\infty}-ball 안으로 projection되며 이를 Projected Gradient Descent(PGD) 공격이라 한다. 이는 표준적이며 강력한 공격으로 간주된다.
Adversarial Defenses
image classification과 OOD detection에 가장 효과적인 방어법은 adversarial training의 변형들이다.
Adversarial Training (AT)
- training과정에서 adversarial example을 활용하여 모델이 adversarial perturbation에 견딜 수 있는 강인한 특징을 학습하도록 한다.
\arg \min_{\theta}\mathbb{E}_{(x,y)\in D_{in}} \left[ \max_{\Vert x-x^{\ast}\Vert_{\infty\le\epsilon}}J(x^{\ast},y;f_{\theta}) \right]
- AT는 perturbation이 없는 sample에 대한 정확도를 감소시키는데 이는 이상 탐지 score에 악영향을 줄 수 있다.
- 따라서 정확도와 robustness 사이에서 더 나은 균형을 이루는 Helper-Based Adversarial Training (HAT)을 baseline으로 제안한다.
Adversarial Learning with inliner and Outlier Exposure (ALOE)
- ALOE는 AT에서의 outlier data에 대한 정보가 부족한 점을 완화하기위해 OE와 유사하게 일부 outlier data를 adversarial training에 포함한다.
- outlier는 uniform distribution label U_{k}로 사용되며 ID와 OOD 모두에 대해 robust한 모델을 얻도록 한다.
\arg \min_{\theta} \mathbb{E}_{(x,y) \in D_{in}} \left[ \max_{\Vert x - x^{\ast}\Vert_{\infty} \leq \epsilon} J(x^{\ast}, y; f_{\theta}) \right] + \lambda \cdot \mathbb{E}_{x \in D_{out}} \left[ \max_{\Vert x - x^{\ast}\Vert_{\infty} \leq \epsilon} J(x^{\ast}, U_K; f_{\theta}) \right]
Open-Set Adversarial Defense (OSAD)
- outlier data를 AT에 포함시키는 대신, training과정에서 더 의미론적인 특징을 학습하려고 한다.
- dual-attentive denoising layer를 model에 추가하여 AT손실과 Adversarial example로부터 깨끗한 image를 복원하는 Autoencoder 손실을 결합한다.
Method
OOD detection은 closed set과 open set data에 더해진 adversarial perturbation에 대해 robust해야한다. 이전 방법들은 약한 attack으로 인해 잘못된 robustness를 제공했다.
end-to-end PGD attack (\epsilon=\frac{8}{255})을 이용해 ALOE, OSAD를 평가했다. 그림을 보면 이 방법들은 충분히 robust하지 않다. 따라서 본 연구에서는 이전 연구들의 단점을 해결하여 보다 robust한 해결책을 제공하고자 한다.
ATD: Adversarially Trained Discriminator
closed set의 robustness에 대한 연구들은 AT 변형들이 가장 효과적인 방어임을 보여준다. 그러나 AT 모델은 정확도와 robustness 간의 상충관계로 인해 accuracy가 낮아진다. OOD detection에서 accuracy는 중요한 역할을 한다. 그리고 AT는 open set sample을 고려하지 않는다. ALOE에서 이 문제를 완화하려 했으나, 이 방법은 open training data가 OOD data의 근사치일 때만 효과적이다. 대부분 이는 성립하지 않는다.
이 문제를 해결하기 위해 본 논문에서는 OpenGAN을 baseline으로 삼았다.
- Discriminator는 in/out binary classification을 수행한다.
- Generator는 closed set과 유사한 image를 생성하여 discriminator를 속이는 OOD image를 만든다.
Generator는 Discriminator를 속이도록 train되므로, generated sample은 discriminator에 대한 자연스러운 adversarial example이 되어 AT에 적합하다. 따라서 이러한 sample에 대해 adversarial attack이 필요없으며, closed set에 대해서만 adversarial perturbation을 가해 discriminator를 AT하면 된다.
이를 Adversarially Trained Discriminator(ATD)라고 한다.
\min_{G} \max_{D} \mathbb{E}_{x \in D_{in}} \log \min_{\Vert x - x^{\ast}\Vert_{\infty} \leq \epsilon} D(x^{\ast}) + \mathbb{E}_{z \in \mathcal{N}} \log \big(1 - D(G(z))\big)
- D : Discriminator
- G : Generator
내부 minimize task는 PGD attack으로 근사하며, 외부 minimize와 maximize는 SGD로 수행한다.
이상적인 Generator가 다양한 OOD distribution을 폭넓게 커버할 수 있도록 Generator가 image대신 feature를 생성하도록 설계했다. 고차원 image보다 저차원 feature를 생성하고 판별하는 것이 더 쉬운 문제이고, 이는 generator를 이상적인 경우에 더 가깝게 만든다.
결과적으로 closed set에서 robust feature를 추출할 수 있는 모델도 필요하다. 이를 위해 HAT 기법을 적용한 pre-trained 모델을 사용한다. last layer는 feature를 얻기위해 제외한다.
마지막으로, OpenGAN과 ALOE와 유사하게 training의 안정성을 위해 open dataset을 사용한다.
ATD의 목적함수는 다음과 같다.
\begin{aligned} \min_{G} \max_{D} \; & \mathbb{E}_{x \in D_{in}} \log \min_{\Vert x - x^{\ast}\Vert_{\infty} \leq \epsilon} D(f_{\theta}(x^{\ast})) + \alpha \cdot \mathbb{E}_{x \in D_{out}} \log \left( 1 - \max_{\Vert x - x^{\ast}\Vert_{\infty} \leq \epsilon} D(f_\theta(x^{\ast})) \right) \\ &+ (1 - \alpha) \cdot \mathbb{E}_{z \in \mathcal{N}} \log \left( 1 - D(G(z)) \right) \end{aligned}
- f_{\theta} : pre-trained robust feature extractor
- \alpha : weight of real open dataset in optimization

이는 ATD의 개략적인 구조를 보여준다.
Toy Example
ATD를 이해하기 쉽게 2차원 toy example을 이용해 시각화한다.
2차원 공간에서 open set과 closed set을 분리된 distribution으로 표현한다. 또한, 이 공간에서 일부 sample을 무작위로 선택하여 생성된 data로 사용한다.
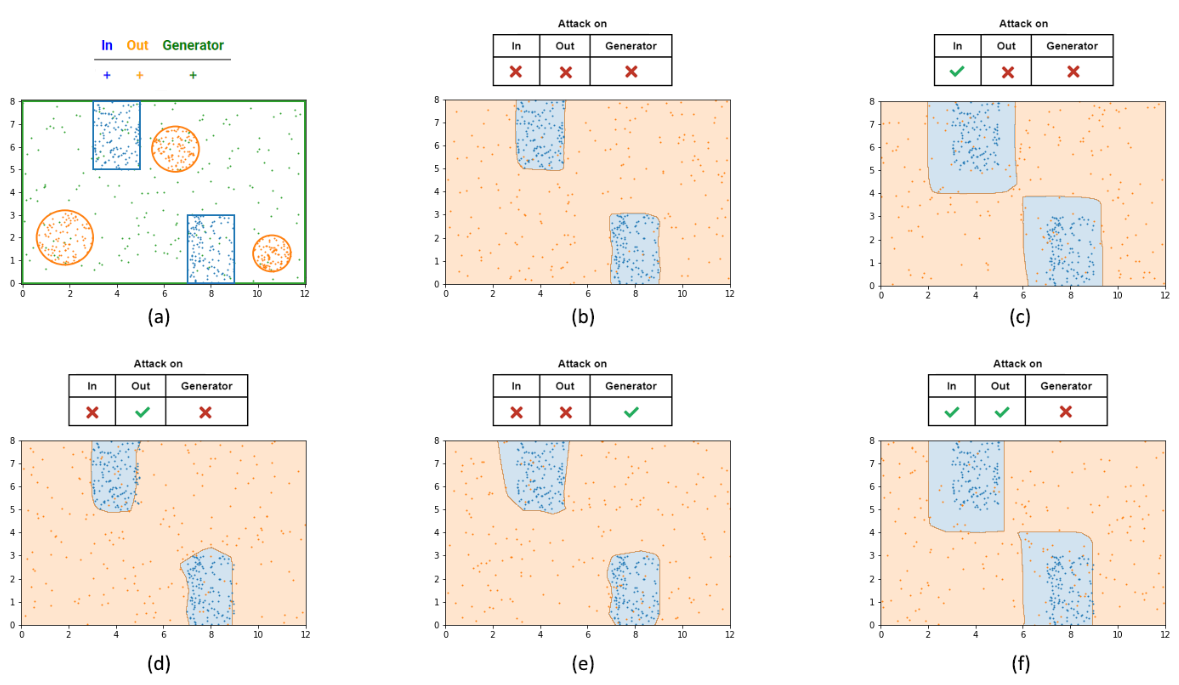
(a)는 사용된 distribution을 보여준다
- blue : closed set
- orange : open set
- green : generated data
multi-layer feed forwarrd neural network를 discriminator로 training하여 이 data들의 in/out binary classification을 수행한다. closed set과 open set은 고정되어 있지만 generated data는 매 epoch마다 다시 sampling되어 ATD training을 한다. 마지막으로, 각 경우마다 discriminator의 output은 공간 전체에 blue(in)와 orange(out)으로 시각화된다.
(b) ~ (f) 까지는 다양한 attack 설정 하에서 OOD detection을 training한 결과이다.
- (b) : 아무 sample도 공격하지 않은 상태
- 모델이 classification decision boundary를 잘 학습했다.
- (c) : ID sample에 대해 \epsilon=1 공격
- closed set 주변의 decision boundary가 더 넓어짐
- ID sample을 잘못 분류하려는 공격에 대한 robustness를 보장한다.
- (d) : OOD sample에 대해 \epsilon=1 공격
- closed set 주변의 decision boundary가 더 좁아짐
- Open set에 대한 공격을 포함하면 OOD data에 대한 robustness는 약간 향상되지만, closed set에 대한 robustness를 감소시킬 수 있다.
- \alpha를 신중하게 선택해야한다.
- (e) : Generated sample에 대해 \epsilon=1 공격
- OOD data에 대한 robustness를 높이지 않는다.
- 이는 generated sample의 불안정성 때문이며, ATD에서는 generated data를 공격하지 않는 이유 중 하나이다.
- (f) : ID, OOD sample을 \epsilon=1 공격
- ATD처럼 open set과 closed set 모두를 공격
- Open set이 존재하지 않는 방향에서 closed set의 margin이 커져 in/out sample 모두에 대한 robustness를 제공한다.
Experiments
- In distribution dataset : CIFAR10 and CIFAR100
- Ouf of distribution dataset : MNIST, TinyImageNet, Places365, LSUN, iSUN, Birds, Flowers, COIL-100
- SVHN은 best discriminator 선택을 위한 OOD validation set
- Food-101은 open training set
Discriminator를 사용하는 방법들 외에 다른 모델들은 MSP, OpenMax, MD, RMD를 사용하여 평가한다.
모든 모델은 \epsilon=\frac{8}{255}의 end-to-end PGD attack에 대해 평가되었다.

- 아무 공격이 없는 standard OOD detection 결과 (Clean)
- In 또는 Out 중 하나만 공격하는 경우 (In / Out)
- In과 Out 둘다 공격하는 경우 (In and Out)
ATD는 두 데이터셋 모두에서 clean detection성능을 유지하면서도 뛰어난 성능을 보였다.

ATD의 black box evaluate를 위해 다른 baseline의 모델들을 이용해 adversarial perturbation을 생성하여 transfer attack을 하였는데 모든 공격에 대해 충분히 robust함을 보였다.

HAT를 사용하지 않고 일반 학습된 모델로 변경하여 효과를 확인하였다. 다른 실험에서는 AT없이 학습을 진행하였다. 이러한 실험의 결과는 ATD만큼 효과적이지 않았다.
Conclusion
- 기존의 OOD detection 방법들은 ALOE나 OSAD와 같은 방법들이 주장한 것과 달리 충분한 robustness를 갖추지 못했다.
- 이 문제를 해결하기 위해 ATD를 제안한다.
- end-to-end PGD attack에 대해 뛰어난 성능을 보이며 black box attack에도 충분히 robust하다.
- 실제 환경에서 요구되는 robustness와 함께 standard OOD detection AUROC 성능도 유지한다.