
논문 링크 : CIDER
"HOW TO EXPLOIT HYPERSPHERICAL EMBEDDINGS FOR OUT-OF-DISTRIBUTION DETECTION?" 논문 리뷰 입니다.
What
- OOD detection을 위한 CIDER라는 새로운 representation learning framework를 제안한다.
- CIDER는 hyperspherical embedding을 사용하여 ID(In-distribution)와 OOD(Out-of-distribution) 데이터의 거리를 통해 OOD data를 구분한다.
Why
- OOD detection은 머신러닝 model이 학습하지 않은 데이터에 대해 신뢰할 수 없는 예측을 방지하기 위해 필수적이다.
- 이 문제를 해결하기 위해 CIDER는 class 간 margin을 크게하고, class 내 응집성을 높여 더욱 정확한 구별을 가능하게 하였다.
How
두가지의 loss function을 도입하여 OOD detection performance를 최적화 하였다.
- Dispersion Loss : class 간 각도 거리를 최대화 하여 class prototype간의 분산을 극대화 하였다.
- Compactness Loss : sample들이 해당 class prototype에 가깝게 위치하도록 하여 class 내 sample이 응집되도록 한다.
Introduction
- Open World에 machine learning model을 배포할 때, OOD input이 있는 경우 model의 신뢰성을 보장하는 것이 중요하다.
- 우리는 input이 알려진 분포에서 추출될 때 정확성 뿐만아니라 학습범주 밖의 미지의 것에 대해서도 인식할 수 있는 모델을 원한다.
- 따라서 OOD detection task가 있으며, Input이 in-distribution(ID)인지 아닌지 결정하는 것이 목표이다.
- 수많은 OOD detection 알고리즘이 개발되었으며, 그 중 distance-based 방법이 유망한 것으로 나타났다.
- Distance-based method들은 모델에서 추출한 feature embedding을 활용하며, test OOD sample이 ID data cluster에서 상대적으로 멀리 떨어져 있다는 가정하에 작동한다.
- Distance-based method의 효율성은 feature embedding의 quality에 따라 크게 달라질 수 있다.
- 최근 SSD+와 KNN+ 같은 연구들은 OOD detection을 위해 기존의 contrastive loss를 사용하고 있으며, 주로 supervised contrastive loss(SupCon)을 활용해 embedding을 학습한 후 parametric Mahalanobis distance, non-parametric KNN distance로 OOD detection 하는데 사용한다.
- 그러나, 이러한 방법들은 ID sample을 분류하는데 충분하지만, OOD sample을 효과적으로 구분하는데 최적화 되어있지 않다.
- 예를들어 CIFAR-10 dataset에서 SupCon loss로 학습한 경우 ID와 OOD 간의 평균 각도 거리가 29.86도에 불과해, 효과적인 ID-OOD 분리를 위해서는 부족하다.
"How to exploit representation learning methods that maximally benefit OOD detection?"
- 이 연구에서는 OOD detection을 위해 설계된 Compactness and DispErsion Regularized learning framework인 CIDER를 제안한다.
- CIDER는 hyperspherical embedding의 특성을 활용하여, von Mises-Fisher(vMF)분포로 모델링 한다.
- vMF는 directional statistics에서 고전적이고 중요한 분포로, unit norm을 가진 feature에 대한 spherical Gaussian distribution과 유사하다.
- CIDER의 핵심 아이디어는 각 sample이 잘못된 class에 비해 올바른 class가 높은 확률을 부여받고, 서로다른 class는 멀리 떨어져 있도록 하는 두가지 특성을 동시에 만족하는 hyperspherical embedding을 vMF 분포의 혼합으로 최적화할 수 있는 end-to-end 학습가능한 loss를 설계하는 것이다.
- 이를 위해 CIDER는 서로 다른 class 프로토타입 간의 각 거리를 크게하는 dispersion loss와 sample들이 자신의 class 프로토타입에 가깝게 위치하도록 하는 compactness loss를 도입했다.
- 이 두 loss는 OOD detection과 ID classification 목적 모두에서 hyperspherical embedding의 형성을 보완한다.
- CIDER는 이전의 contrastive loss와 달리, vMF분포의 latent representation을 명시적으로 공식화하여 hyperspherical embedding의 직접적인 이론적 해석을 제공한다.
- 특히, class간 분산을 크게 촉진하는 것이 강력한 OOD detection 성능의 핵심이다.
- SSD+를 포함한 이전의 방법들은 SupCon loss를 사용하므로, OOD detection에 필요한 충분한 class 간 분산이 부족한 embedding을 생성한다.
- CIDER는 class간의 큰 마진을 명시적으로 최적화하여 이러한 문제를 완화하고, 보다 바람직한 hyperspherical embedding을 만든다.
- CIFAR-10으로 학습했을 때 CIDER는 SupCon에 비해 상대적으로 42.36% 향상된 ID-OOD 분리 성능을 보여준다.
- CIDER의 강력한 representation은 다양한 distance-based OOD 점수에 도움이 되며, 최근 경쟁 방법인 SSD+, KNN+를 큰 차이로 능가한다.
Preliminaries
multi-class classification을 고려한다.
- X : input space
- Yin=1,2,…,C : ID label
- Dintr=(xi,yi)Ni=1 : PXYin 으로 부터 i.i.d 추출된 training set
- PX : X의 marginal distribution : in-distribution(ID)
Out-of-distribution detection
OOD detection은 sample x∈X가 PX(ID)인지 OOD 인지 결정하는 binary classification problem으로 설명된다.
OOD data는 label set이 Yin과 교차하지 않는, 모델이 예측해서는 안되는 관련없는 분포의 sample이 해당된다.
- Doodtest : OOD test set
- Yood∩Yin=∅
ID(1) 인지 OOD(0) 인지 아래의 수식에 의해 결정된다.
Gλ(x)={1if1{S(x)≥λ}0if1{S(x)<λ}
- 높은 S(x) score가 ID로 분류된다.
- λ는 ID data의 높은 비율(95%)이 올바르게 분류되도록 선택
Hyperspherical embeddings
- hypersphere는 위상공간(topological space)로, standard n-sphere과 동형사상(homeomorphic)이다.
- 이는 n+1차원 유클리드 공간에서 중심으로부터 일정한 거리에 위치해있는 점들의 집합을 말한다.
- sphere의 반경이 1인 경우 unit hypersphere라고 부르며, 공식적으로 Sn:={z∈Rn+1|‖z‖2=1}
- 기하학적으로 hyperspherical embedding은 hypersphere의 표면에 놓여있다.
Method

CIDER의 전체적인 구조는 2가지 구성 요소로 이루어져 있다.
- input data를 고차원 feature embedding으로 mapping한다.
- Encoder f:X↦Re
- augmented input ˜x↦f(˜x) (끝에서 두번째 층의 출력)
- projection head를 통해 고차원 embedding을 저차원 embedding으로 변환하고, 이 embedding을 정규화 하여 unit hypersphere위에 놓이게 한다. 정규화된 embedding을 hyperspherical embedding이라고도 한다.
- projection head h:Re↦Rd
- lower dimensional feature representation ˜z:=h(f(˜x))
- normalized feature embedding z:=˜z/‖˜z‖2
CIDER의 목표는 학습된 embedding이 ID data와 OOD data를 구별하는데 가장 효과적일수 있도록 hyperspherical embedding space를 형성하는 것이다.
Model Hyperspherical Embedding
hyperspherical embedding은 von Mises-Fisher(vMF)분포로 자연스럽게 모델링 할 수 있다.
특히, vMF는 unit norm(‖z‖2=1)인 feature z에 대한 spherical Gaussian distribution과 유사하다.
pd(z;μμc,κ)=Zd(κ)exp(κμμ⊤cz)
- class c 인 unit vector z∈Rd 의 pdf
- μμc : class prototype with unit norm
- κ≥0 : 평균 방향 μμc를 중심으로 한 분포의 tightness
- Zd(κ) : normalization factor, 적분하여 1이 되도록 함.
- κ값이 클수록 평균 방향으로 더 강하게 집중되고, κ=0인 경우, sample point가 hypersphere에 균일하게 분포된다.
P(y=c|z;{κ,μjμj}Cj=1)=Zd(κ)exp(κμμ⊤cz)∑Cj=1Zd(κ)exp(κμμ⊤jz)=exp(μμ⊤cz/τ)∑Cj=1exp(μμ⊤jz/τ),κ=1τ
How to optimize Hyperspherical Embeddings?
Training objective
핵심 아이디어는 두가지 속성을 동시에 만족하는 hyperspherical embedding을 vMF의 혼합물로 최적화 할 수 있는 학습가능한 loss function을 설계하는 것이다.
- 각 sample이 잘못된 class보다 올바른 class에 대해 더 높은 확률을 가지도록 한다.
- 서로 다른 class들은 멀리 떨어지도록 한다.
To achieve 1
training data에 대한 MLE
argmaxθN∏i=1p(yi|zi;{κj,μμj}Cj=1)
- N : training set의 크기
- i : embedding의 index
negative log-likelihood를 취함으로써, 목적함수는 아래의 loss를 최소화 하는 것과 같다.
Lcomp=−1NN∑i=1logexp(z⊤iμμc(i)/τ)∑Cj=1exp(z⊤iμμj/τ)
- c(i): sample xi 의 class index
- τ : temperature parameter
Compactness Loss : sample이 class prototype에 가깝게 위치하도록 유도한다.
To promote property 2
Dispersion Loss : 서로 다른 class prototype간의 큰 각도거리를 촉진하여 class들이 멀리 떨어지도록 유도한다.
Ldis=1CC∑i=1log1C−1C∑j=11{j≠i}eμμ⊤iμμj/τ
각 거리가 큰 prototype들은 ID classification 정확도에는 영향을 미치지 않을 수 있지만, OOD detection에는 중요한 요소이다. OOD sample의 embedding은 ID cluster들 사이에 위치하기 때문에 class간 margin을 크게 최적화하면 OOD detection에 도움이 된다.
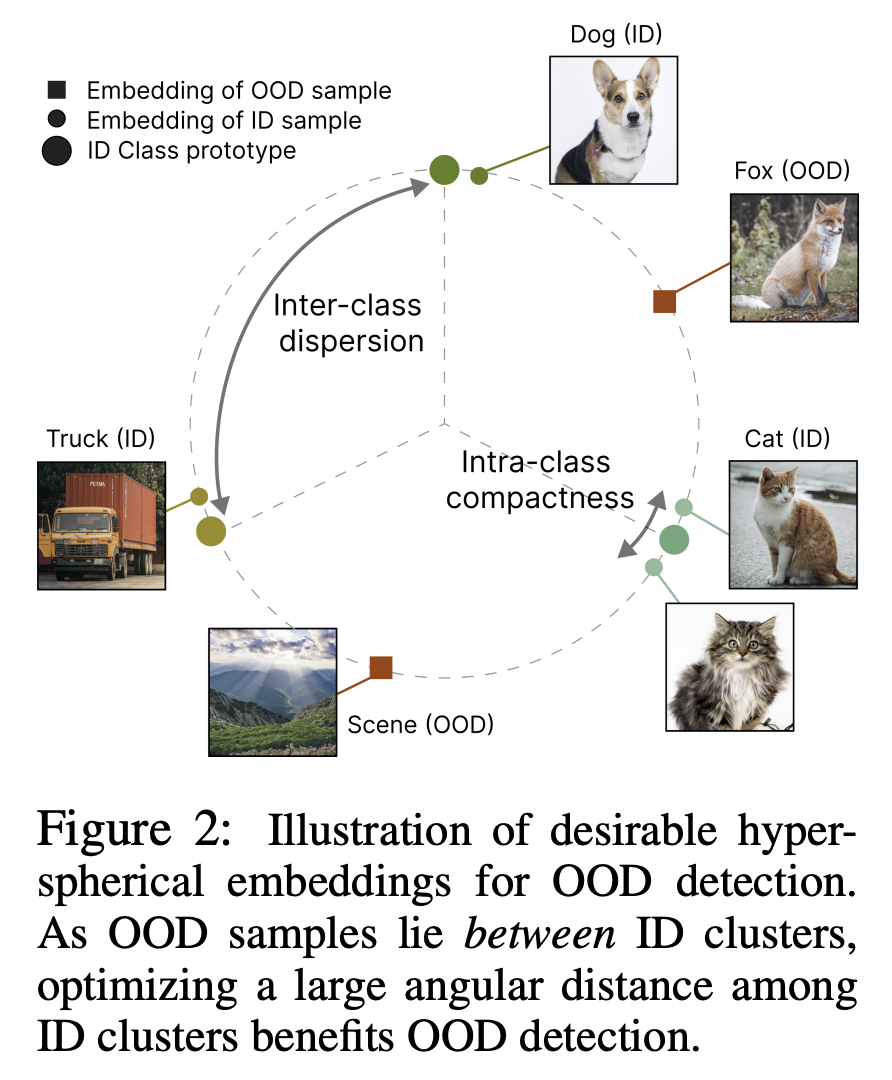
- 여우(OOD) sample이 고양이(ID), 개(ID)에 의미적으로 가까운 것을 볼 수 있다.
- hyperspherical space에서 고양이와 개의 각도 거리가 클수록 여우와의 분리 가능성이 더 향상되고, 효과적으로 탐지할 수 있다.
- λc : 두 loss의 상대적 중요성을 조절하는 계수
- CIDER : compactness and dispersion regularized learning
LCIDER=Ldis+λcLcomp
Prototype estimation and update
학습하는 동안 중요한 단계는 각 class c=1,2,…,C에 대한 class prototype μc를 추정하는 것이다.
- class prototype : 각 class의 중심을 대표하는 vector
가장 간단한 방법은 μc를 각 class에 속하는 모든 training sample들의 평균 벡터로 추정하는 것이지만, 계산 비용이 크고, 바람직하지 않은 학습 지연을 유발한다.
그 대신 exponential-moving-average 방식을 이용해서 class-conditional prototype을 효율적으로 업데이트 할 수 있다.
μμc:=Normalize(αμμc+(1−α)z),∀c∈1,2,…,C
z는 새로 입력된 data sample의 embedding vector로 unit hypersphere 위에 위치한다.
α가 클수록 이전 μμc의 영향이 더 커지고, 1−α가 클수록 z의 영향이 커진다. 즉 α는 새로운 데이터를 얼마나 반영할지, prototype이 얼마나 빠르게 변화할지를 결정한다.
Experiments
Common Setup
Datasets and training detail
- in-distribution dataset으로 CIFAR-10, CIFAR-100을 사용하였다.
- OOD test dataset으로 SVHN, Places365, Textures, LSUN, iSUN을 포함하는 자연 이미지를 사용한다.
- backbone으로 ResNet-18(CIFAR-10), ResNet-34(CIFAR-100)을 사용하였다.
OOD detection scores
- 테스트 시간 동안 OOD detection을 위한 거리 기반 방법이 사용된다.
- input x가 embedding space의 ID data에서 상대적으로 멀리 떨어져 있으면 OOD로 간주한다.
- 기본적으로, feature space에 분포가정을 하지 않는 간단한 non-parametric KNN distance를 사용한다.
- 여기에서 distance는 k번째 최근접 이웃과의 cosine similarity이고, 모든 feature가 unit norm을 가지고 있으므로 negated Euclidean distance와 동등하다.
- ablation study에서는 SSD+와 공정한 비교를 위해 Mahalanobis score도 고려한다.
Evaluation metric
- FPR95 : ID sample의 True Positive Rate가 95%일 때 OOD sample의 False Positive Rate
- AUROC
- ID ACC : ID classification의 정확도
Main Results and Analysis
CIDER outperforms competitive approaches.
- OOD deteciton을 위한 다양한 경쟁 방법들이다.
- 모든 방법은 auxiliary outlier dataset을 가정하지 않고 CIFAR-100을 사용하여 ResNet-34에서 학습되었다.
명확성을 위해 contrastive loss가 있는지 없는지 두 범주로 방법을 구분하였다.
- Without Contrastive loss : MSP, ODIN, Mahalanobis, Energy, GODIN
- 1~4의 방법은 모델이 softmax cross-entropy를 통해 학습되었다.
- 5의 방법은 DeConf-C loss를 사용하여 학습되었다.
- With Contrastive loss : ProxyAnchor, SimCLR, CSI, SSD+, KNN+
- SSD+와 KNN+는 모두 SupCon loss를 사용하여 훈련된다.
- 동일한 network structure와 embedding dimension을 사용하였으며, training objective만 다르게 설정하였다.
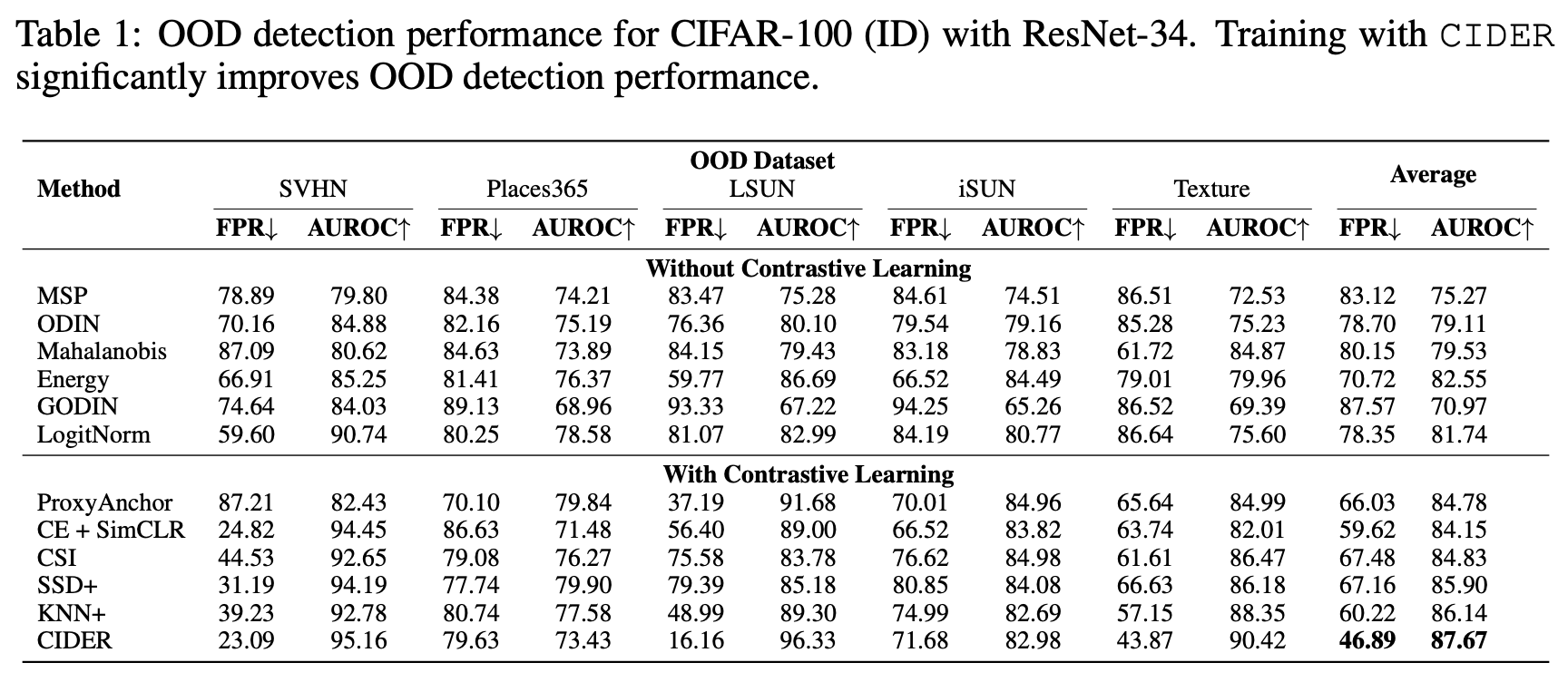
Table 1에서 CIDER를 사용하면 OOD detection의 성능이 상당히 향상하는 것을 볼 수 있다.
세가지 trend를 관측할 수 있다.
- SSD+, KNN+와 비교하여, CIDER는 class간 dispersion을 명시적으로 최적화하여 더 바람직한 embedding을 생성한다. 또한 CIDER는 OOD detection을 위한 class-conditional Gaussian을 완화하고, 대신 간단한 non-parametric distance-based score로 충분하다. 구체적으로 CIDER는 FPR95에서 SSD+보다 20.3%, KNN+보다 13.3% 더 뛰어난 성능을 보인다.
- CSI는 복잡한 data augment와 앙상블에 의존하는 반면 CIDER는 기본적인 data augmentation을 사용하기 때문에 더 간단하다. CSI와 비교하여 CIDER는 평균 FPR95를 20.6%감소시켰다.
- 향상된 embedding quality로 CIDER는 CE loss를 사용하는 학습에 비해 ID accuracy를 0.76% 향상시켰다.(Table 9)
CIDER benefits different distance-based scores
CIDER의 강력한 representation이 다른 거리기반의 OOD 점수에 이점을 줄 수 있다.
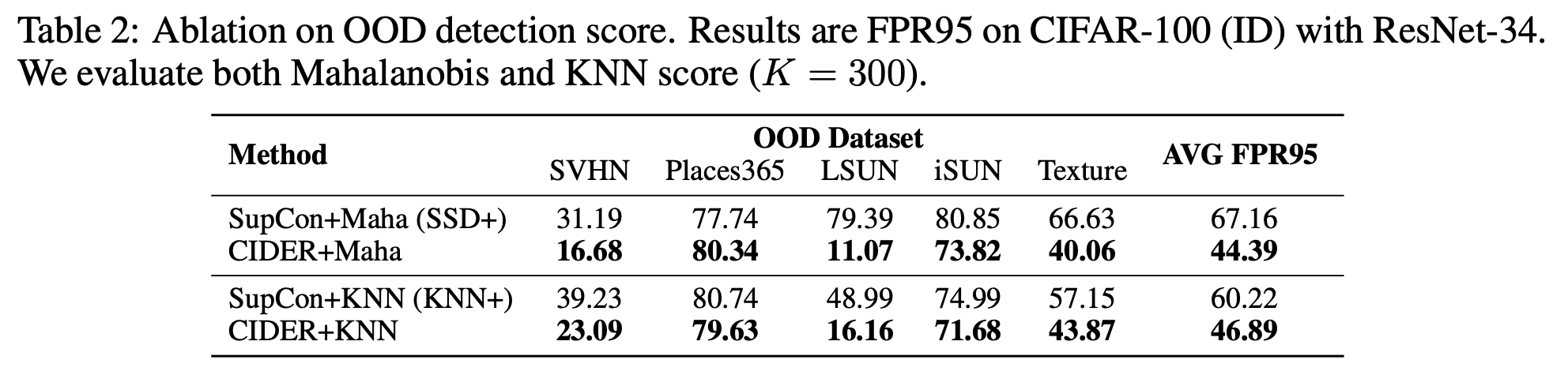
CIDER + Maha(Mahalanobis) : SSD+ 에 비해 평균 FPR95를 22.77% 감소시켰다.
- SSD+와 공정한 비교를 위해 Mahalanobis score 사용
CIDER + KNN : KNN+ 에 비해 평균 FPR95를 13.33% 감소시켰다.
이는 CIDER의 향상된 representation quality와 일반성을 더 강조한다.
Inter-class dispersion is key to strong OOD detection
Loss의 구성요소 들이 OOD detection에 미치는 영향을 조사
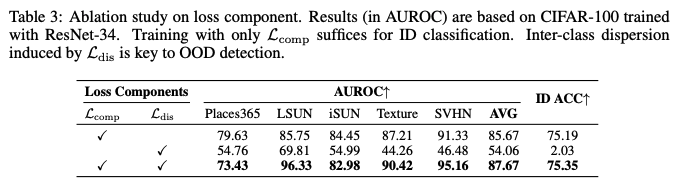
- ID classification의 경우 Lcomp 만으로 훈련하면 ID ACC 75.19를 얻을 수 있으며, SSD+의 ID ACC인 75.11과 유사하다.(Table 9) 이는 Lcomp가 class 내 compactness를 촉진하고, sample-prototype간 negative pairs로 인한 적절한 수준의 class 간 dispersion을 통해 ID class들을 구별하는데 충분하다.
- OOD detection의 경우, class 간 dispersion이 중요하며, Ldis를 통해 명시적으로 권장된다. Ldis를 추가할 경우(Lcomp+Ldis) 평균 AUROC가 2%증가하였다. 그러나 Lcomp없이 Ldis만 사용하면 ID classification이나 OOD detection 모두 충분하지 않다.
분석 결과 Lcomp와 Lcomp의 시너지효과를 통해 ID classification과 OOD detection 모두에 바람직한 hyperspherical embedding을 개선한다.
Characterizing and Understanding Embedding Quality
CIDER learns distinguishable representations

- (a)에서 CIDER가 CE에 비해 훨씬 더 압축성이 뛰어난 것을 알 수 있다. 또한, class가 space에 더 균일하게 분포되어 dispersion loss의 효과를 강조한다.
CIDER improves inter-class dispersion and intra-class compactness
시각화 뿐만 아니라 embedding quality도 정량적으로 측정한다.
Dispersion(μμ)=1CC∑i=11C−1μμ⊤iμμj1{j≠i}Compactness(Dintr,μμ)=1CC∑j=11nn∑i=1z⊤iμμj1{yi=i},
- Dintr={xi,yi}Ni=1
- zi : xi의 normalized embedding
Dispersion은 class prototype들의 평균 cosine similarity로 측정된다.
Compactness는 각 feature embedding과 해당 class prototype간의 평균 cosine similarity로 해석된다.
더 쉽게 해석하기 위해, cosine similarity를 angular degree로 변환하였다. 즉, 각도가 크면 class-prototype들 사이의 분리가 더 잘 된다는 것을 의미한다.
마찬가지로, Compactness는 각도가 낮을 수록 좋다.
CIFAR-10을 기반으로 한 비교
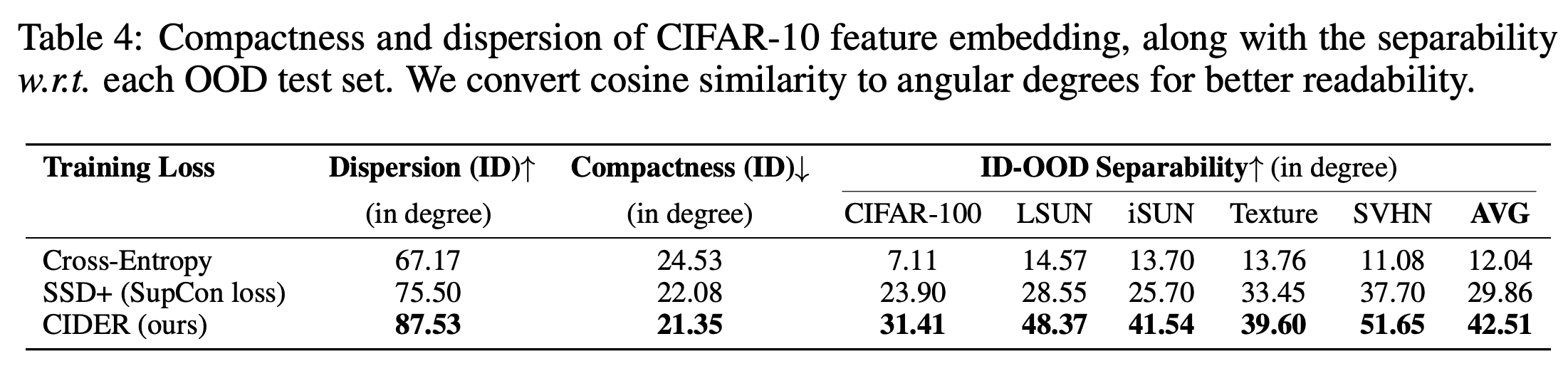
- SSD+와 비교하여 CIDER는 Dispersion을 12.03도 향상시켰다.
SupCon과 달리, CIDER는 class간 분산을 명시적으로 최적화하여 OOD detection에 유리하다.
CIDER improves ID-OOD separability
feature embedding의 quality가 ID-OOD 분리가능성에 어떻게 영향을 미치는지 정량적으로 측정한다.
separability score를 도입하여, OOD test set의 sample embedding이 가장 가까운 ID class prototype과 평균적으로 얼마나 가까운지 ID sample(ID sample과 prototype간의 거리)과 비교하여 측정한다.
높은 separablility score는 OOD test set을 더 쉽게 탐지할 수 있음을 나타낸다.
↑Separability=1|Doodtest|∑x∈Doodtestmaxj∈[C]z⊤xμμj−1|Dintest|∑x′∈Dintestmaxj∈[C]z⊤x′μμj
- Doodtest : OOD test dataset
- zx : sample x의 normalized embedding
위의 Table 4는 CIDER가 더 뛰어난 ID-OOD Separability를 보여주며, 결과적으로 뛰어난 OOD detection 성능을 보여준다.(Table 1 참조)
5개의 OOD test dataset을 평균한 결과 SupCon에 비해 ID-OOD Separability를 42.36%((42.51-29.86)/29.86) 개선하였다. 이 결과는 OOD detection을 개선하기 위한 CIDER의 효율성을 입증한다.
Additional Ablations and Analysis
CIDER is competitive on large-scale datasets
large-scale의 dataset에 대해서도 CIDER는 매우 경쟁력 있는 성능을 유지하며, SupCon을 지속적으로 능가한다. 이는 class 간 분산과 class 내 응집성을 명시적으로 촉진하는 것의 이점을 다시 확인할 수 있다.
Conclusion and Outlook
- OOD detection을 위해 hyperspherical embedding을 활용하는 새로운 framework를 제안한다.
- CIDER는 dispersion과 compactness를 최적화하여 강력한 ID-OOD 분리성을 촉진한다.
- 대규모 OOD detection task를 포함한 task에서 우수한 성능을 달성했다.
- 향후 OOD detection을 위해 hyperspherical representation을 활용하는 방법에 영감을 줄 수 있길 희망한다.